Billing overview | You are not charged for activating Alibaba Cloud Model Studio. But you are charged for model inference when using large language models (LLMs) for text generation. View bills: Go to Bill Details and Cost Analysis. View calling statistics: Go to Model Observation. |
Billable items | Model inference (calling) |
Model inference (calling) | Overview & free quotaFor a complete list of prices and free quotas, see Models. For detailed performance information, see Throttling. You can view the number of calls and token consumption for a specific model in Model Observation. Flagship modelsFor prices and free quotas of other models, see Models. Flagship models |  Qwen-Max Qwen-Max
Best inference performance | Qwen-Plus Balanced performance, speed and cost | Qwen-Turbo Fast speed and low cost | Maximum context (Tokens) | 32,768 | 131,072 | 1,008,192 | Minimum input price (Million tokens) | $1.6 | $0.4 | $0.05 | Minimum output price (Million tokens) | $6.4 | $1.2 | $0.2 |
Batch discountText generation models qwen-max, qwen-plus, qwen-turbo support batch calling. The cost for batch calling is 50% of real-time calling. Batch calling does not support discounts such as free quota or context cache. You can submit batch tasks as files for asynchronous execution. The system processes large-scale data offline during non-peak hours and returns the results when the task is completed or when the maximum wait time is reached. You can use batch inference tasks through console or API. Context cacheEnabling context cache does not require additional payment. If the system determines that your request hits the cache, the hit tokens will be charged as cached_token. The tokens that are not hit will be charged as input_token. The unit price of cached_token is 40% of the unit price of input_token. output_token is charged at the original price.

The cached_tokens property of the return result indicates the number of tokens that hit the cache. If you use the Batch mode, the discount of context cache is not available. For more information, see Context Cache. |
FAQ | Billing rulesHow to calculate token count?Tokens are the basic units used by models to represent natural language text, which can be understood as "characters" or "words". For Chinese text, 1 token usually corresponds to 1 Chinese character or word. For example, "你好,我是通义千问" will be converted to ['你好', ',', '我是', '通', '义', '千', '问']. For English text, 1 token usually corresponds to 3-4 letters or 1 word. For example, "Nice to meet you." will be converted to ['Nice', ' to', ' meet', ' you', '.'].
Different models may have different tokenization methods. You can use the SDK to view the tokenization data of the Qwen model locally. You can use this local tokenizer to estimate the token amount of your text, but the result may not be completely consistent with the actual server. If you are interested in the details of the Qwen tokenizer, see Tokenization. How to view calling statistics?You can check the call count and token consumption for a specific model on the Model Observation page of the console. How is multi-round conversation billed?In multi-round conversations, the input and output from previous interactions are all billed as new input tokens. I created an LLM application and never used it. Am I billed for the application?No, you are not. Creating an application alone does not incur charges. You are only billed for model inference if you test or call the application. Cost managementHow to pay?If you encounter a balance shortage or overdue payment while using Model Studio, visit Expenses and Costs to pay. How to set monthly consumption alert?You can set quota alert in the Expenses and Costs center. 
How to stop the pay-as-you-go billing?You cannot stop pay-as-you-go billing. But as long as you stop using the features of Model Studio, you will not incur fees. To prevent unexpected API invocation fees, you can delete all your API Key. 
Additionally, you can set monthly consumption alert. You will be notified immediately in case of unexpected charges. About billsView the costs of Model StudioGo to the Cost Analysis page. Select Pretax Amount for Cost Type. Select Month for Time Unit. Select Alibaba Cloud Model Studio for Product Name.

View the costs of model inferenceGo to the Cost Analysis page. Select Pretax Amount for Cost Type. Choose a time range. Select Model Studio Foundation Model Inference for Product Detail.

View the inference costs of a specific modelGo to the Billing Details tab of the Bill Details page. Select a Billing Cycle. Select Model Studio Foundation Model Inference for Product Details. Click Search. Take qwen-max as an example: In the Instance ID column, you can find the input_tokens and output_tokens instances of qwen-max. Add the amounts of the two instances to get the cost of calling the qwen-max model.

How to allocate costs based on payment details?Bills generated after September 7, 2024, can be allocated based on: workspace ID, model name, input/output type, and calling channel. Go to the Billing Details tab of the Bill Details page. Select a Billing Cycle. Select Model Studio Foundation Model Inference for Product Details. Click Search. Click Export Billing Overview (CSV) to download the search results. Allocate the costs based on Instance ID. The Instance ID, such as text_token;llm-xxx;qwen-max;output_token;app, represents billing type;workspace ID;model name;input/output type;calling channel.
Calling channels include app, bmp, and assistant-api. app refers to model calls through applications, bmp to calls made on the Home or Playground pages of the console, and assistant-api to calls through the Assistant API. 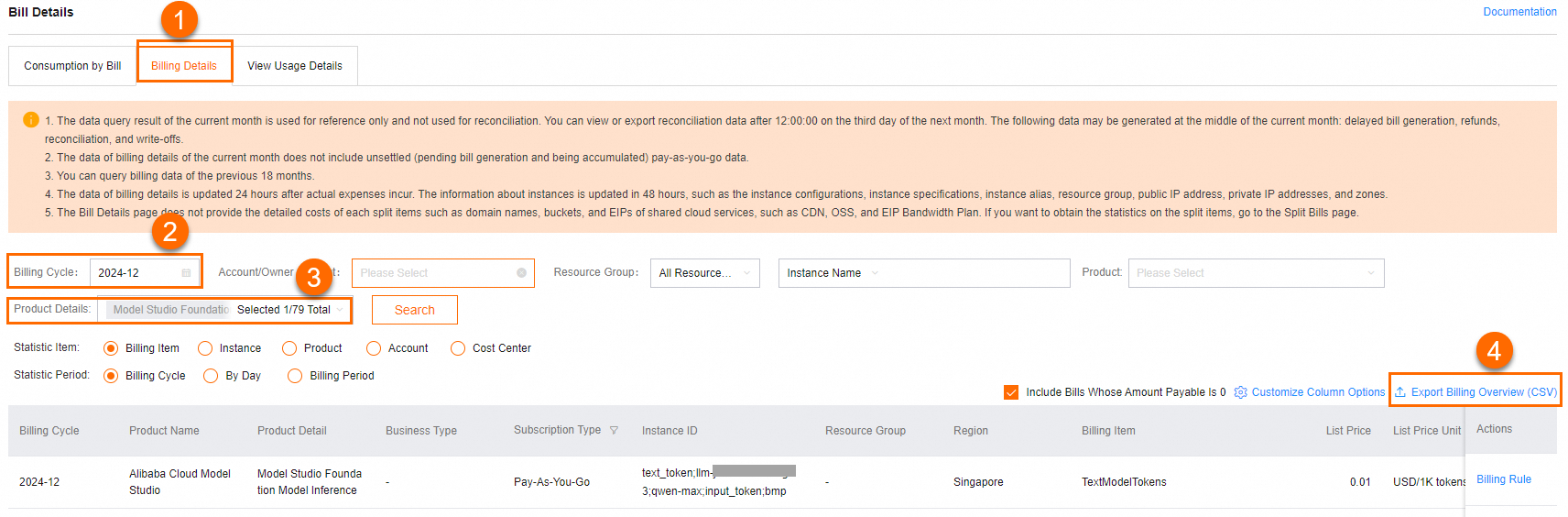
About APIAPI errors: Service activation or account balance1. Service not activated Use your Alibaba Cloud account to log on to Expenses and Costs. Activate Model Studio and claim the free quota. 
2. Insufficient account balance 3. Set consumption alert to prevent repeated errors |